Blog Post
9.10.2020
Cruise’s Continuous Learning Machine Predicts the Unpredictable on San Francisco Roads
Share

The promise of all-electric, self-driving vehicles is monumental: they will keep us safer on the road, help make our air cleaner, transform our cities, and give us back time. To make this possible, we are working towards developing an autonomous vehicle (AV) which, among other things, is able to understand and predict the world around it at a superhuman scale. This is the engineering problem of our generation and the cutting edge of AI.
One of the core challenges of autonomous vehicles is accurately predicting the future intent of other people and cars on the road to make the correct decisions. Will that pedestrian cross the road in front of us? Is that car about to cut us off? Will the car in front of us run the yellow light or hit the brakes? People don’t necessarily follow the rules of the road, and answers to these questions are often quite fuzzy, which is why we take a machine-learning-first approach to prediction.
Our machine learning prediction system has to generalize to both completely nominal events as well as events that it sees very infrequently (“long tail” events). Examples of long tail situations include vehicles performing U-turns or K-turns, bicycles swerving into traffic, or pedestrians unexpectedly running into the street.
The biggest challenge with prediction is not building a system that is able to handle the nominal cases well, but rather building something that generalizes well to uncommon situations and does so accurately.
Predicting the long tail requires data
One important task is to ensure that rare events are sufficiently represented in the dataset. As with any ML system, a model will only scale as well as its training data, so addressing dataset imbalance must be a primary focus. Once we are able to expose our model to sufficient training examples, it should be able to learn to predict long tail situations effectively.
It is important to note that these long tail events do exist in the data we see on the road, but they are rare and infrequent. As a result, we focus on finding the needle in the haystack of regular driving and use upsampling to teach the models more about these events.
A naive approach to identifying rare events is to hand engineer “detectors” for each of these long tail situations to help us sample data. For example, we could write a “u-turn” detector and sample scenarios any time it triggers. This approach would help us collect targeted data, but quickly breaks down when it comes to solving for scale because it’s impossible to write a detector specific enough for each unique longtail situation.
Insight 1: Prediction data can be auto-labeled using our perception stack
At its core, a predicted trajectory is a representation of what we believe someone is going to do in the future. When we possess the ability to observe what that person does in the future, evaluating a predicted trajectory becomes straightforward by comparing it against the observed trajectory. Said another way, future perception output can be compared against our current predictions to create a self-supervised learning framework. This enables Cruise engineers to use our perception stack to label data for our prediction models.
Imagine that our AV predicts that the car in front of it will turn left in the upcoming intersection. After observing the car, we see that they did not turn left, but rather proceeded straight through the intersection instead.

By comparing the AV’s prediction (a trajectory that turns left) with its future perception (a trajectory that goes straight), our engineers can easily create labels for our prediction without requiring any human input. In this example, the model incorrectly predicts the vehicle to follow a trajectory that turns left, but we can identify the correct trajectory as one that goes straight.
This is in direct contrast to many other ML tasks, such as object detection, where human annotators are commonly used to label “ground truth”. Human annotation is time-consuming, error-prone, and/or expensive. In contrast, we auto-label our data using observation of future behavior from our perception system.
Insight 2: Auto-labeling data allows for automated failure mining
The self-supervised framework described above for identifying an incorrect left turn trajectory enables the creation of an active learning framework where error situations can be automatically identified and mined.
To build diverse, high coverage datasets — and in turn, high quality models — our goal is to upsample data from any and all error scenarios, not just ones that have explicit detectors available for them. An auto-labeled approach facilitates maximum coverage in our dataset because it is able to identify and mine all errors from our models, ensuring that no valuable data is missed. It also keeps the dataset as lean as possible by ensuring that we don’t add more data for scenarios that are already solved.
The self-supervised framework for auto-labeling data combined with an active learning data mining framework creates Cruise’s home-grown Continuous Learning Machine (CLM), an entirely self-serving loop that addresses the data sampling challenge and scales to meet even the most challenging longtail problems.

Cruise’s Continuous Learning Machine (CLM) solves long tail prediction problems
Below is a break down of what each section of the above diagram represents:
Drives: The CLM starts with our fleet navigating downtown San Francisco where our vehicles are exposed to challenging situations 46 times more frequently than in suburban environments. Despite this, long tail maneuvers such as U-turns comprise less than 0.1% of our observed data.
Error Mining: Utilizing active learning, error cases are automatically identified and only scenarios where we see a significant difference between prediction and reality are added to the dataset. This enables extremely targeted data mining, ensuring we add only high-value data and avoid bloating our datasets with a copious amount of “easy” scenarios.
Labeling: The self-supervised framework labels all of our data automatically using future perception output as “ground truth” for all prediction scenarios. The core CLM structure extends to other ML problems where a human annotator can fill in, but fully automating this step within prediction enables significant scale, cost, and speed improvements that allow this approach to truly span the entirety of the long tail.
Model Training and Evaluation: The final step is to train a new model, run it through extensive testing, and deploy it to the road. Our testing and metrics pipelines ensure that a new model exceeds the performance of the previous model and generalizes well to the nearly infinite variety of scenarios found in our test suites. Cruise has invested significantly in our ML infrastructure, which allows a variety of time-consuming steps to be heavily automated. As a result, we can now create an entire CLM loop without requiring human intervention.
Putting the Continuous Learning Machine into practice
Below is a series of examples that showcases a variety of scenarios our models experience infrequently but have been exposed to enough within the dataset to be able to make an accurate prediction.
U-turns
Human drivers may encounter another motorist making an abrupt (and sometimes illegal) U-turn sporadically. Even with our cars navigating the streets of San Francisco at all times, we see less than 100 U-turns each day on average, making U-turns an ideal candidate for the CLM. Below are a few examples of U-turns that our AVs encounter.

Example 1 represents a busy intersection where all vehicle trajectories that leave the intersection via the top right exit lane are highlighted in red. We see that most of the dataset contains drivers moving straight with a small number of left turns, an even smaller number of lane changes, and only two U-turn trajectories.
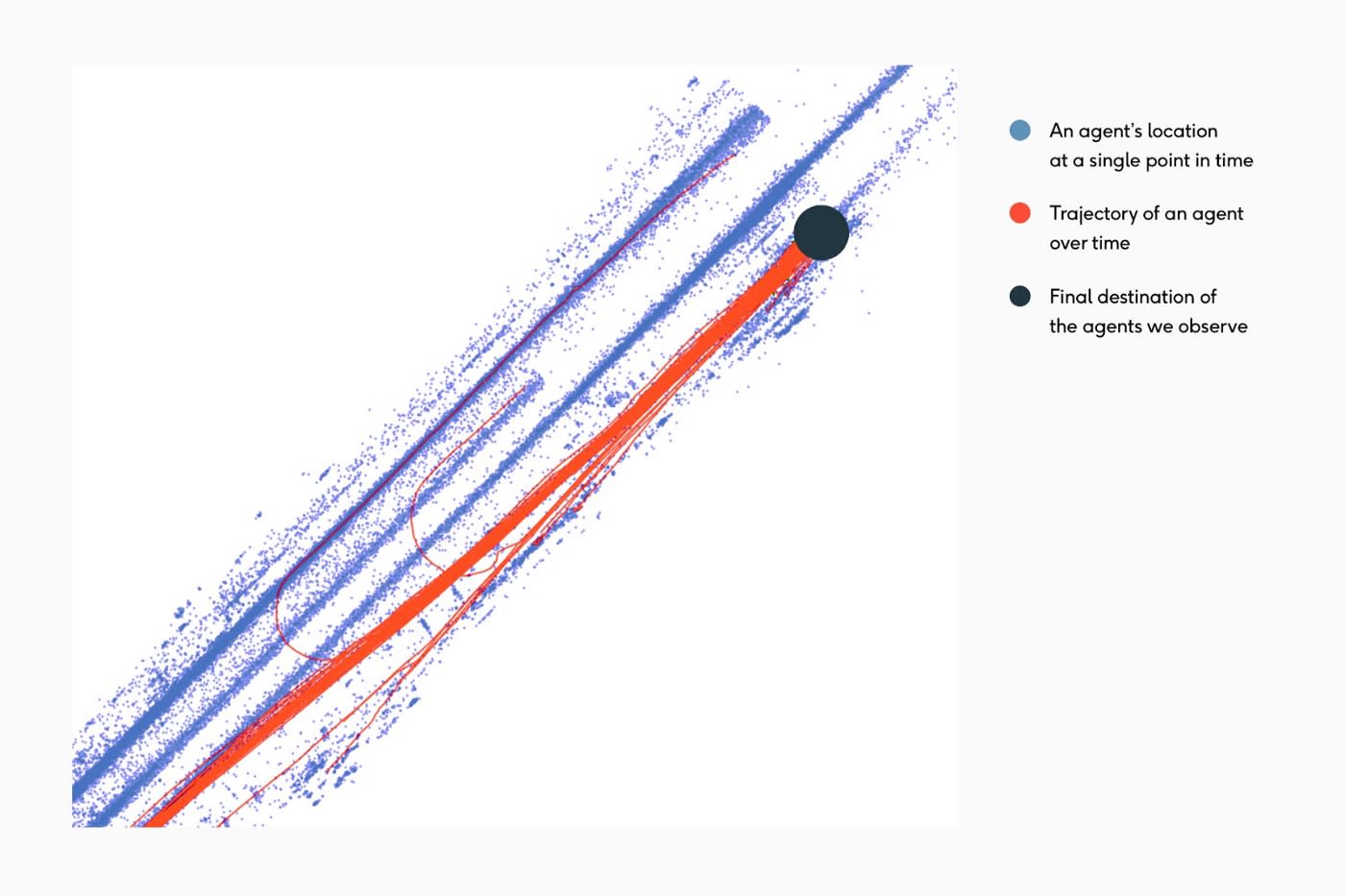
We also see examples of mid-block U-turns (Example 2), as well as intersections — but again, they are very sparse in our data.
Applying our CLM principles, an initial deployment of our model may not optimally predict U-turn situations. As a result, when we sample data, error situations commonly include U-turns. Over time, our dataset steadily grows in representation of U-turns until the model can sufficiently predict them and the AV can ultimately navigate these scenarios accurately.

In the video above (Example 3), the cyan-blue line shows that the model recognizes the vehicle in front of us is in the early stages of a U-turn. The vehicle has barely entered the intersection, but the model has been exposed to enough examples within the dataset to accurately make this prediction.
K-turns
The K-turn is a three-point turn where the driver must maneuver both forwards and in reverse in order to turn around into the opposite direction. These are uncommon and most often used when the street is too narrow for a U-turn, meaning we see examples approximately half as frequently.
Example 4 represents what a K-turn trajectory looks like in our data as a vehicle completes a K-turn, then immediately pulls into a parking spot on the other side of the road. Again, despite seeing K-turns so rarely, we are able to predict this direction change mid-maneuver.

In the video below (Example 5), the car in front of us is perpendicular to the lane and moving backwards as it completes the second stage of a K-turn. Following the cyan blue predicted trajectory, the prediction for this vehicle is first to continue moving backwards, then pause and drive forward while turning into the correct direction to follow the nearby lane.

Cut-ins
Another interesting phenomenon we observe is people changing their trajectory for slowing or stationary objects ahead of them. This often leads to people cutting in front of nearby cars as they attempt to move around the object in front of them.
Example 6 represents an example trajectory from our dataset. We see the vehicle move over into the next lane temporarily, then return to their lane once they have passed the obstacle.
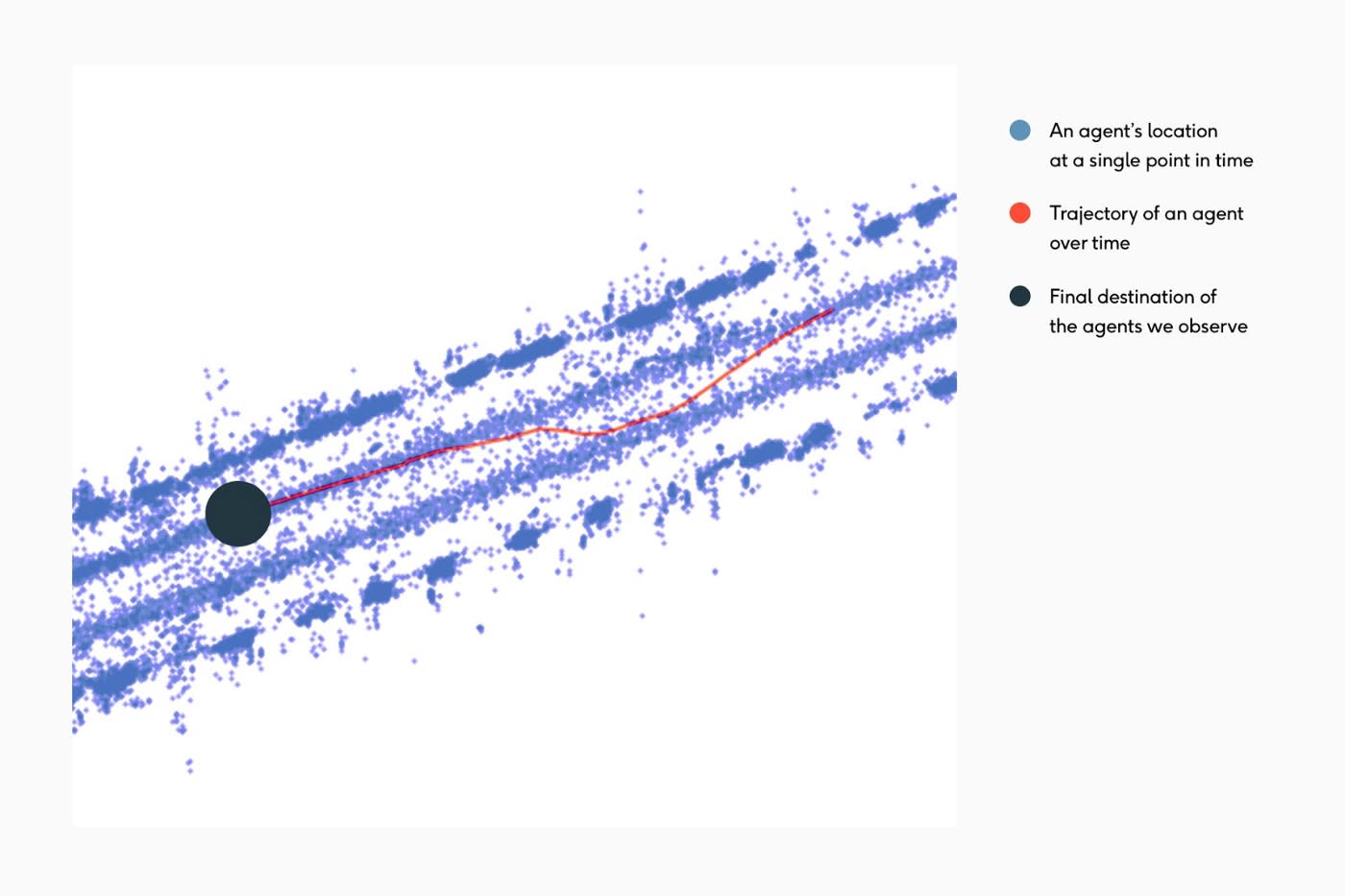
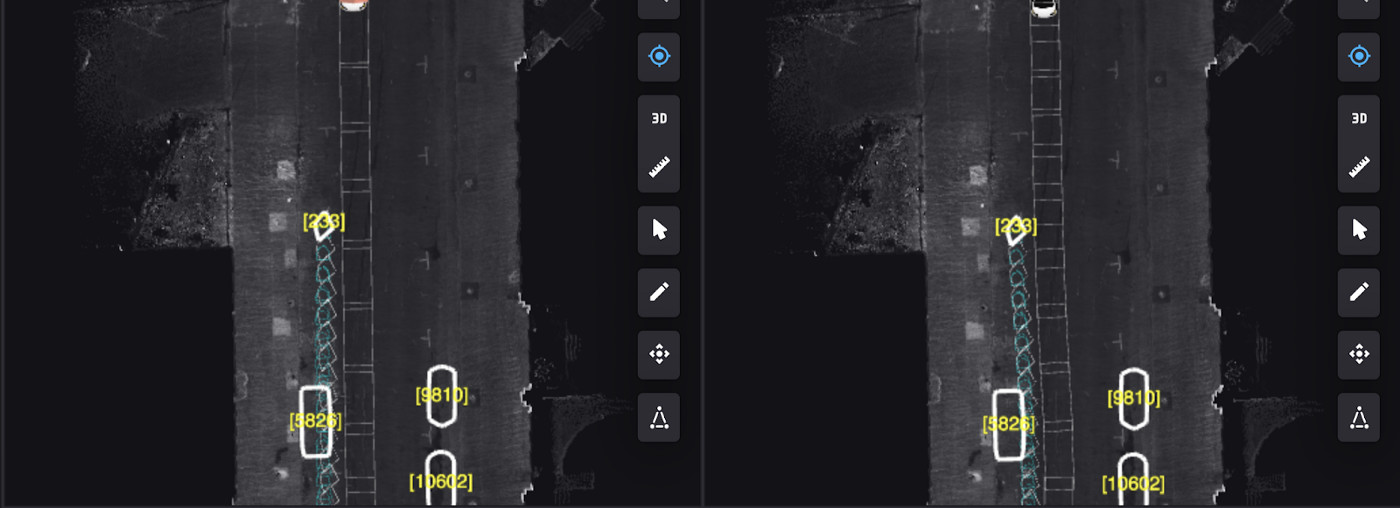
Cut-ins are common in both vehicles and bicycles. For instance, Example 7 depicts a before-and-after following a round of data mining. On the left, the bicycle trajectory passes through the stationary parked car — which is an unrealistic trajectory. After a round of data mining, we get the trajectory on the right where we are now able to predict the bike to move around the parked car instead.
In the video below (Example 8), there is a bus stopped in the right lane at a bus stop, which encourages the car behind it to overtake it. This car then cuts in front of the Cruise AV very suddenly. Situations like this require us to predict such behavior early so that the Cruise AV can slow down preemptively and give this car enough space to go around.

The future of ML is in Autonomous Vehicles
Despite the challenge of predicting the long tail behaviors of others on the road, building a scalable ML solution is very achievable. The problems we are solving in AV, such as generalizing across the long tail, are at the core of machine learning.While this blog discussed prediction primarily as a single agent problem, e.g. “what will that specific object do next”, prediction is actually a multi-agent problem. We need to understand both the intent of other agents on the road, and reason about the sequence and interactions between different agents and how they will evolve over time. The complexity of this problem is it’s own field of research, which is another reason why autonomous vehicles are the greatest engineering challenge of our generation.The future of ML is happening in Cruise. Join us if you’re interested in pushing ML across the next frontier.