Blog Post
4.17.2023
AV Compute: Deploying to an edge supercomputer
Share

Introduction: The Fully Driverless AV problem
The compute workload for executing the L4 fully driverless Autonomous Vehicle (AV) function is massively compute- and data-intensive, often featuring multiple AI models to carry out the tasks from perception to planning+control. In this article, we describe a vertically integrated, tightly-coupled HW/SW approach to addressing the growing computational complexity, while ensuring minimal disruption to engineering velocity.
The term fully driverless is used not merely for effect but to communicate an essential expectation:
The AV must be capable of driving fully autonomously 100% of the time
This is to draw a distinction with the L2-L3 ADAS function where there is an expectation of an alert safety driver, who must be prepared to quickly take over. Driving the car autonomously 90% of the time may be extremely desirable in the ADAS context but would be disastrous in the AV context. As with most complex problems, the biggest challenges are in that last 10%, often called the “long tail”. Per the ninety-ninety rule conquering the long tail problem (or the last 10%) typically involves 90% of the effort, which is what makes the AV function so challenging to productionize.
Here at Cruise, we are solving this already complex problem in the city of San Francisco, arguably one of the most hectic urban environments in the nation. To date, our AVs have already accumulated over 1,000,000 miles of fully autonomous miles (i.e., without a safety driver) on SF streets. From here, we are scaling to new cities while deepening our presence in SF. Cruise is on this path right now to demonstrate how we can scale AV deployment practically and safely. The narratives and threads of innovation and creativity that weaves through the engineering fabric of Cruise are rich and heartening although at times painstaking.
In this article, we will follow one thread of complexity - the compute thread. Specifically, we explore how to deploy an increasingly complex AV software stack on a shrinking AV hardware budget without compromising engineering agility. We demonstrate that a possible approach to addressing this complexity is to focus on a vertically-integrated HW/SW platform that must be designed and optimized synchronously. We make the case that vertical integration of our stack allows us to sidestep the complexity of making every layer in the stack fully general and allows us to focus only on the parts important to AV deployment.
AV Workload demands
Let’s start by looking at the AV workload shown in the figure below. The AV driving function can be described by these major subsystems within the AV workload:
Sensor data: there are several sensors on AVs typically (camera, lidar, radar, etc) that define the range and field of sensing capabilities.
Perception: processes the sensor inputs to create a model of the scene / environment around the AV.
Tracking: identifies and tracks (across frames) all the objects in the scene.
Prediction: is responsible for predicting the path that these tracked objects will take in the future
Localization + mapping: defines the current position of the AV in the scene.
Freespace: identifies the open/free drivable region.
Planning: takes all this as input to determine the path that the AV will drive.
Controls: converts the planning outputs to drive commands that are executed on the AV.
The challenge is to execute this complex AV software stack under tight real-time latency budgets.
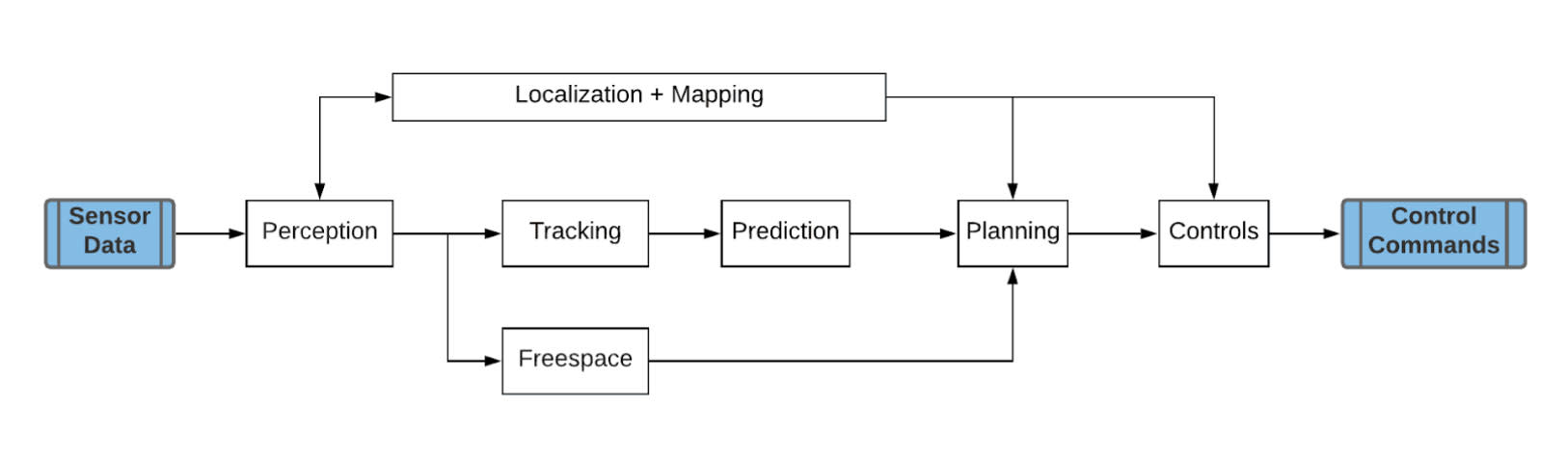
Figure: The AV workload
Diversity of workloads
Traditionally, AI naturally fits into the perception subsystem which is heavily based on sensor understanding. At Cruise, there is an active shift to introduce AI into the rest of the subsystems (like prediction, tracking, planning) as we find that AI-based algorithms are much more resilient to a diversity of scenarios than traditional heuristic algorithms. Below are some of the SOTA algorithms used in the AV stack.
Sensor/Problem domain | SOTA approaches |
|---|---|
Perception (Camera) | Application of transformer architectures (e.g., from speech) to build vision-transformers are showing promising results |
Perception (LiDAR/ Radar) | |
Prediction | CNN + Attention modules |
Planning, Joint planning prediction | RL style with ML for value and policy networks |
These ML models sometimes employ specialized architectures that are specific to the AV problem. For example, take sparse convolutions - these are very useful in processing 3D point clouds generated by lidar and radar. The ops, data-structures and optimizations required to deploy sparse-conv models are very different from those employed for dense convolutions (e.g., grid downsampling/upsampling, building neighborhood maps etc.). As a result, the software ecosystem (e.g., Tensorflow, pytorch) does not provide out-of-box support. On the hardware side, GPUs and ML accelerators are designed to operate on dense, coalesced data; so the data-structures and indirect data-lookups featured in sparse-conv barely harness the hardware’s roofline capacity thus rendering traditional ML architectures (like GPUs) to be under-utilized.
Real time system requirements
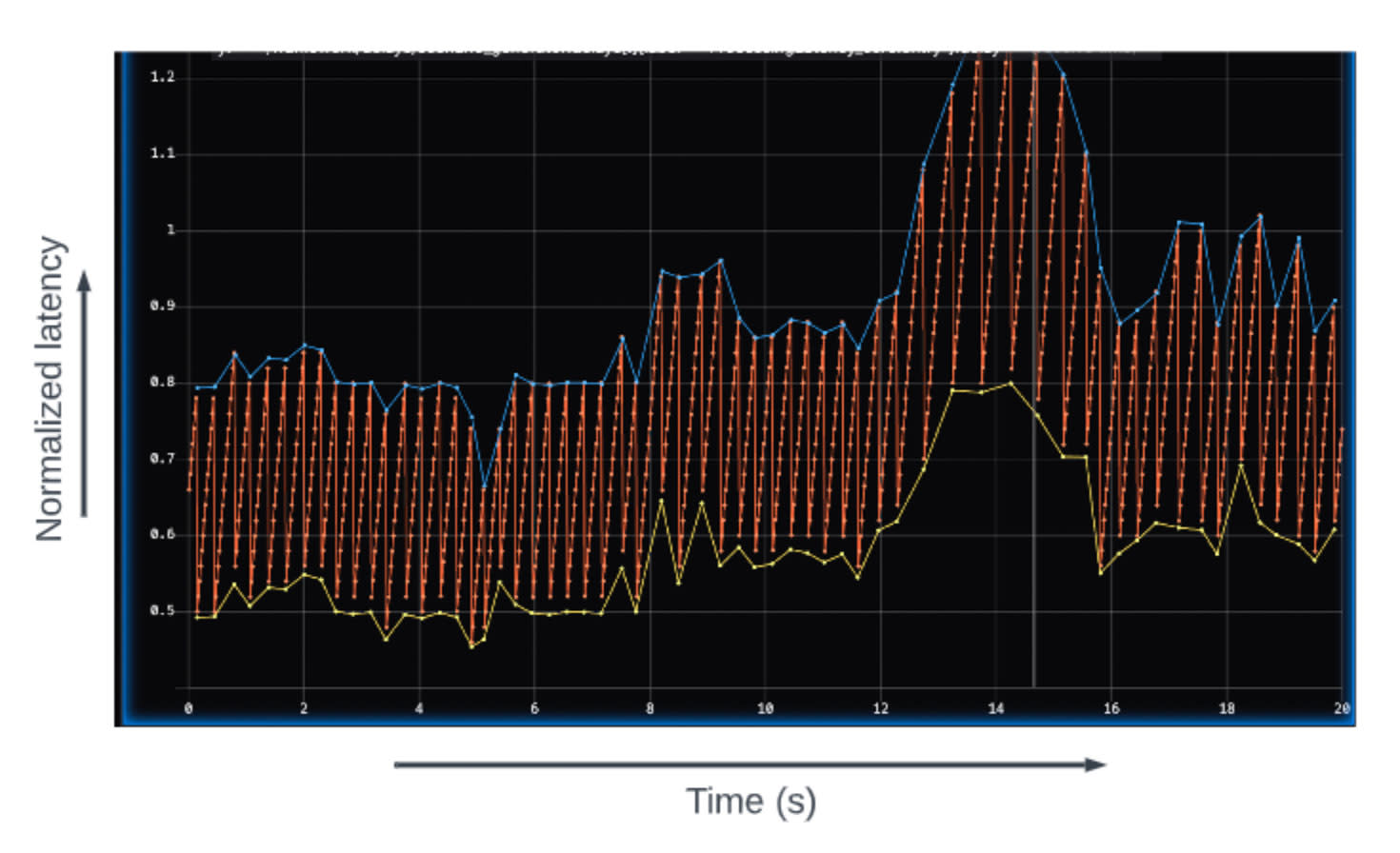
A principal challenge is that the AV must react to a highly dynamic environment under tight real-time latency requirements that must account for the worst-case scenarios to ensure safety and reliability. The major driver of dynamism is the scene complexity, e.g. number of tracked objects. To illustrate, the figure above shows the AV workload e2e latency distribution for a single scenario -- clearly there's a lot of variance in latency. In fact, when the computation takes longer, there are second order effects like increase in contention for the same fixed hardware resources which can further exacerbate issues unless they’re handled appropriately.
The challenge is that the critical path of execution is not static and is sensitive to on-road scenarios. This means that the critical path may change dynamically, requiring the runtime environment to favor or optimize for the critical path tasks (e.g., by isolating resources) while ensuring that hardware utilization is maximized by accommodating the non-critical path tasks concurrently.
In order to meet the latency goals, we need a runtime scheduler that is capable of adapting to this dynamic environment by being aware of certain system states in order to make the correct choices that prioritize the critical path. Generic schedulers from hardware vendors (e.g., CUDA scheduler) typically come with fixed priority to stream mappings. Due to these restrictions, building a custom runtime scheduler is essential to squeeze out efficiency and real-time performance.
AV Deployment ecosystem
Scaling AVs and solving the long-tail requires engineering agility. This is especially challenging when we consider the complexity in the AI lifecycle for AV deployment as shown in the figure below.
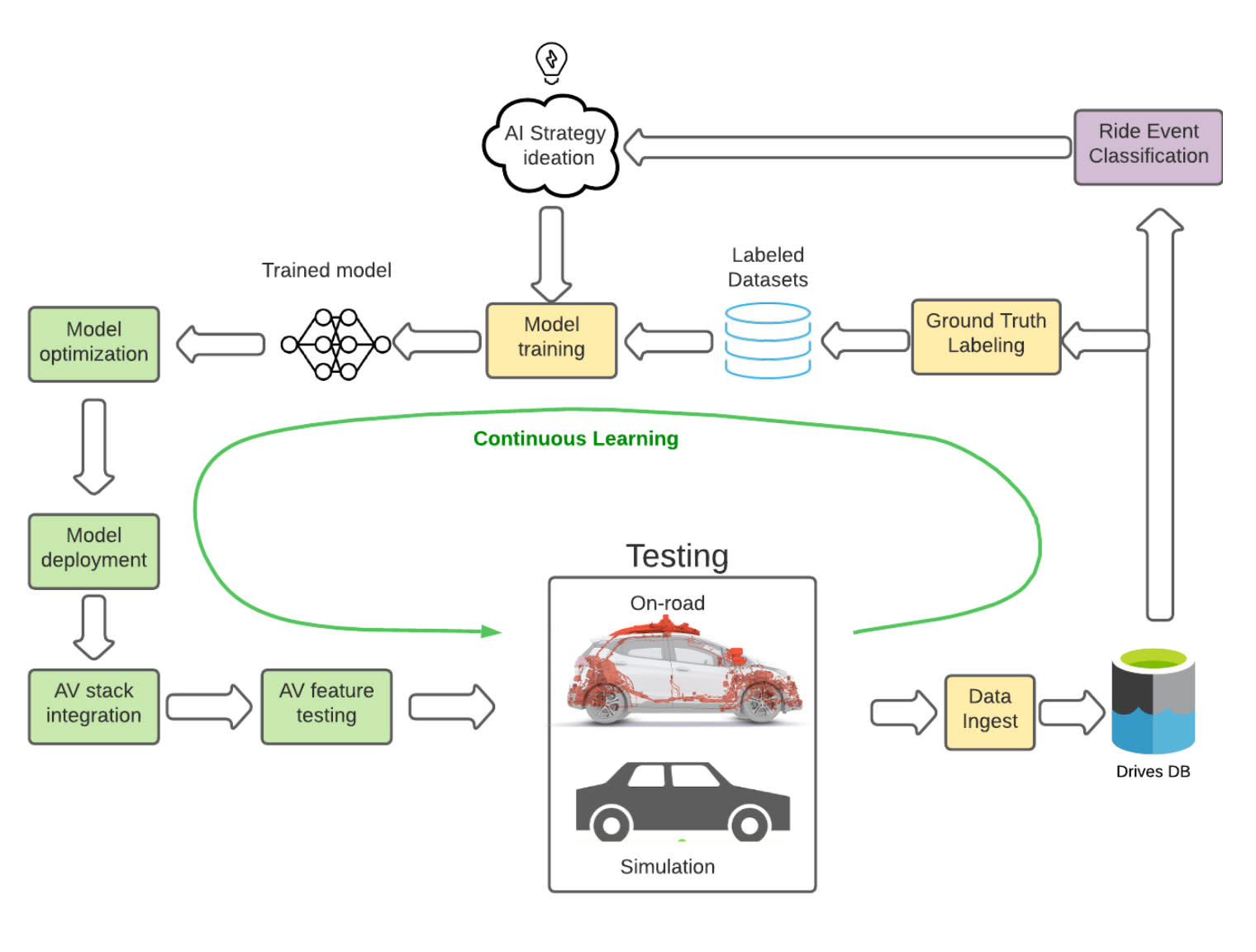
Figure: End-to-end AI / AV feature development lifecycle
AV feature development cycle starts with data - peta-bytes of drive data is generated everyday from our testing fleet. This AV’s performance is analyzed to understand what the AV is doing well and what needs improvement. In parallel, the data is labeled and ground-truthed to create labeled datasets for training our AI models. Based on the analysis of AV drive data, a set of AV features and AI models are identified for development.
The AI models are trained on Cruise’s ML platform using popular DL frameworks like PyTorch and TensorFlow. Model optimization may be applied during training (e.g., Quantization Aware Training) or in a post-training step. Next, the model is converted from the DL framework (PyTorch / TensorFlow) script to runtime binaries that are performant (within latency budgets) and meet the safety and reliability constraints. These binaries are then integrated into the AV stack and undergo a CI testing pipeline. The final step is road-testing, which can be either real, on-road testing or on our real-world simulation platform. Safety and reliability metrics collected from all this testing informs the release acceptance criteria.
Engineering agility requires that this entire AV feature development cycle is fast, automated, performant and reliable. We have accomplished this at Cruise by building a Continuous Learning Machine platform so that this cycle can be iterated automatically to continuously improve the performance of the entire AV fleet. Obviously this poses several automation challenges: building automated data pipelines, data-mining, neural architecture search (NAS), automated optimization and automated compilation to integrate into the AV stack.
In this section, we will specifically explore the challenges in ML model optimization and deployment to AV stack. This is challenging because of the real-time performance and reliability constraints for AV runtime. Typically, in most enterprise AI solutions, deployed AI models run inference within a DL framework’s runtime environment (like TFRT, PyTorch-jit), which manages scheduling and execution of inference. For AVs, such DL framework runtimes cannot be deployed directly due to reliability and performance issues. Moreover, the diversity in ML employed in the AV stack complicates this challenge further.
We are building out the required ecosystem here at Cruise. The main goals are: (a) automation that is critical to realizing the vision of the continuous learning machine, (b) the deployed models must operate with tight latency budgets and (c) retargetability across HW platforms to account for changes in future generations.
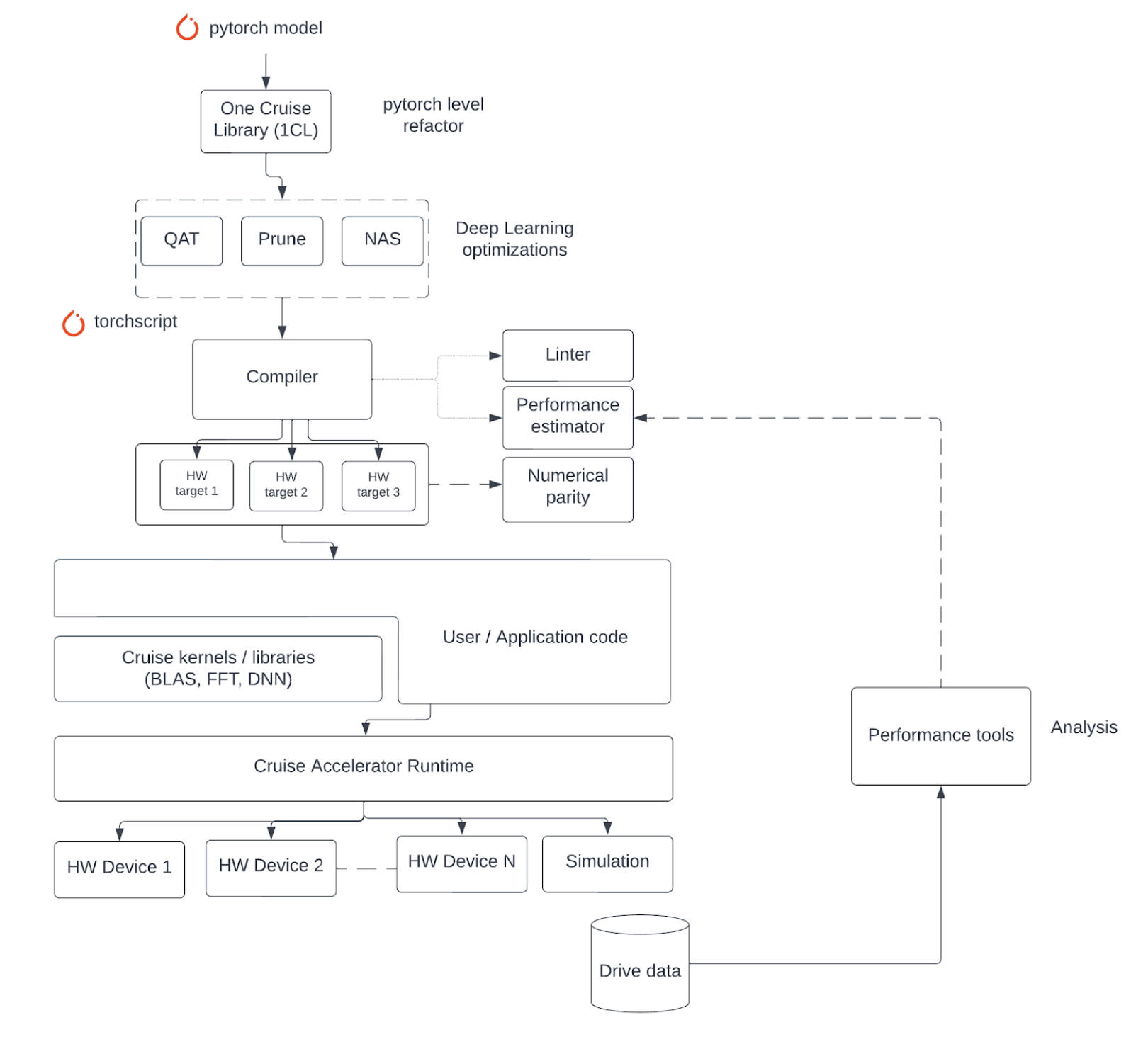
Figure: The ML deployment ecosystem
The figure above outlines the SW ecosystem for AV deployment. It starts with a trained ML model (in, say, pytorch) as input. We first apply a series of optimizations to improve the latency / performance of the model and then automatically convert it to runtime binaries. Below is a salient list of some of these components.
One Cruise Library (1CL): This is a DSL (Domain Specific Library) that is authored at the pytorch level. It’s specifically designed for automatic compilation of performant kernels that participate in the inference function. Rather than a fixed set of functionality, the library specifically focuses on parallelism patterns in algorithms. Designing ML models and customizing them for performance are typically two different skill sets. Rather than sequence them manually, ML engineers express their models in 1CL (pytorch-based) which is automatically compiled into performant runtime kernels.
Deep Learning Optimization (DLO): This is a deep learning optimization toolkit that does source to source transformation on pytorch models with the goal of discovering equivalent models that have better runtime but with equivalent AV functional performance. The main optimizations are quantization, weight pruning and Neural Architecture Search (NAS).
Compiler: It automates conversion of ML models to runtime binaries thereby boosting engineering velocity, while supporting retargetability to multiple HW platforms. For each target, the compiler partitions the pytorch graph to map execution on different compute domains / devices. It optimizes execution for the chosen target and generates performant runtime binaries. The Cruise compiler IR is built using the MLIR framework. It forms a common basis on top of which different tools (like linter, debugger and performance estimator) can be built.
Compute Libraries: We maintain optimized implementations for kernels/operations that are performant on each target HW platform. The twin goals (which sometimes compete) are performance and portability. These libraries are generally composed from lower level primitives all of which are exposed to the compiler. The goals for the libraries are high performance without sacrificing portability.
Cruise Accelerator runtime; In the absence of DL framework runtimes (e.g., TF runtime, Torch/JIT), execution of ML inference is orchestrated by our runtime, which manages scheduling, resource allocation, data movement, synchronization and execution orchestration, while exposing control to the compiler. At the core of the runtime is the inference server, which owns all models and manages inference requests from different nodes in the AV stack.
Performance tools: First, we need “road to code” tools to assess performance issues from an existing AV drive segment on the road. These include profiling tools (for real-time logging) and analysis/visualization tools that can provide system-level insights and map bottlenecks to specific code segments in the AV stack. Second, we need “code to road” tools that ensure, proactively, that any code changes do not introduce regressions due to performance. These include performance estimation tools to guide early feature design choices (against potentially poor performance) as well as a robust, high-fidelity offline testing platform that catches potential regressions.
To summarize, the components of the AV deployment ecosystem are essential to ensuring that we can maintain engineering velocity, while delivering high runtime performance and being nimble enough to target future, low-cost AV hardware platforms.
AI Hardware spectrum
In the previous section, we discussed the degree of customization needed in the software ecosystem to foster engineering velocity. But, what about the AV hardware platform itself? As we scale our commercialization efforts, the volume of AVs that are manufactured and the operating fleet size necessitates a low-cost, highly reliable and safe platform. The table below describes a classification of AI hardware solutions in the market today.
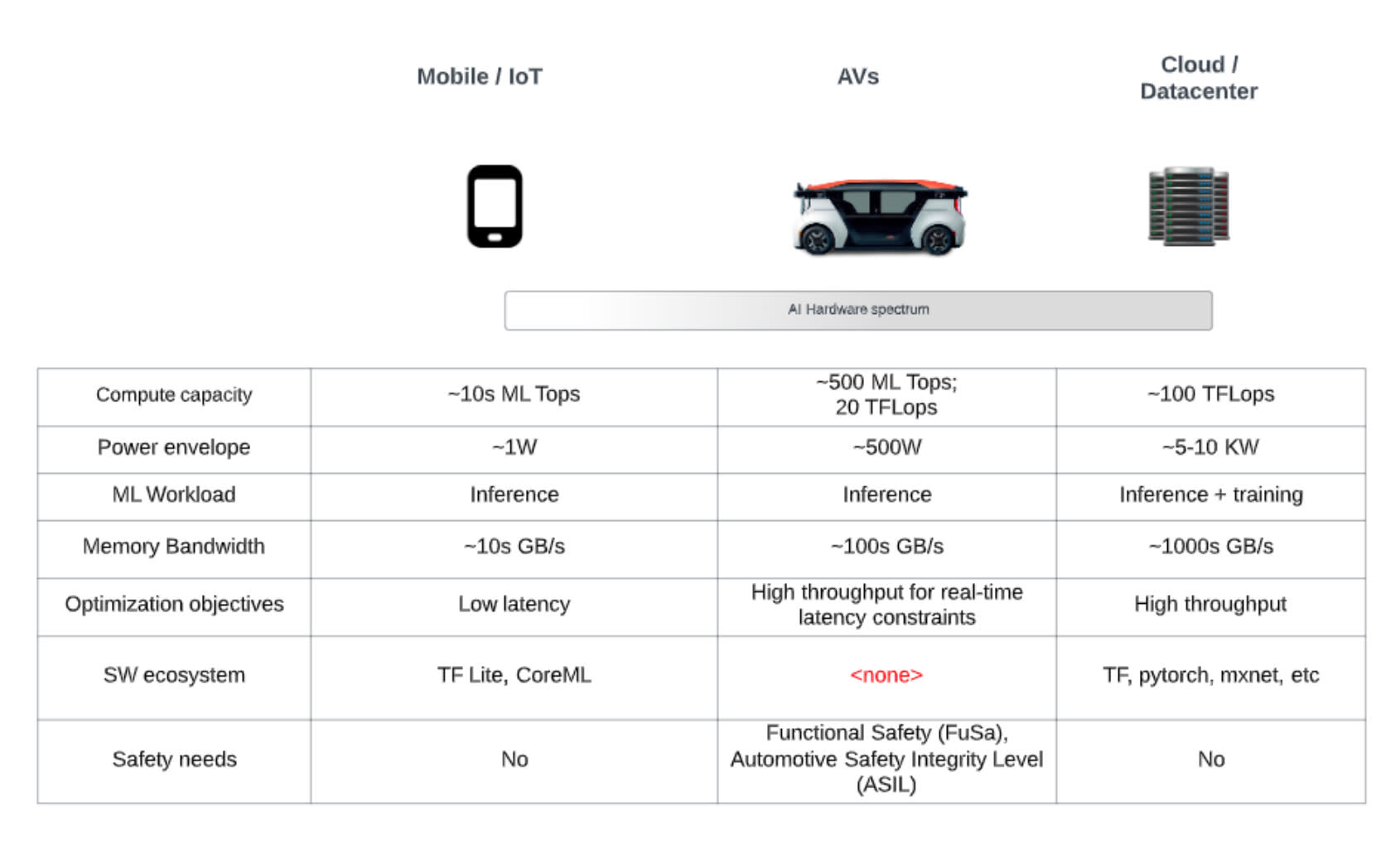
Figure: AI hardware spectrum by workload type
AI hardware’s boom in recent years was originally spurred by the HPC investments made by Nvidia GPUs. With the growth of AI, this has evolved into AI hardware that is racked into the cloud and private data centers forming the basis for AI training, enterprise AI solutions and cloud-native AI deployments. These are typically the biggest ML supercomputers providing large compute capacity for scaling out workloads. On the other end of the spectrum is the tiny ML domain driven by the mobile and IoT markets. Here, power and cost constrain the compute capacity.
The requirements of the AV use-case fall somewhere in the middle of this spectrum. The AV workload requires ML supercomputer-like capacities (provided by the cloud AI hardware) but is also edge deployed, meaning that power, cost and other constraints apply (like the mobile/IoT use-case). So, in essence, the AV use-case requires us to deploy ML on to an edge supercomputer creating a host of new challenges. Also, noteworthy, is the last two rows of the table above: the absence of a AV software ecosystem (as described in previous section) and the absence of safety-critical features, e.g., AVs need to guarantee FuSa (Functional Safety), SOTIF (safety of the intended function) and follow all the safety best practices and requirements (e.g., ASIL qualification).
AI datacenter hardware is typically capable but not cost-efficient and not safety-certified at large volumes. On the other hand, tiny ML hardware may be power/cost efficient but don’t scale with the compute needs. Therefore there is an opportunity to vertically integrate the AV hardware and software system in the interest of low-cost scaling. In addition, doing so provides the opportunity to customize AV hardware with AV specific requirements, e.g., designing for specialized compute cores (like sparse convolutions), sizing HW resources (cores, SRAM, DRAM bandwidth), etc.
We are starting to see some off-the-shelf autonomous driving hardware platforms in the market, e.g., Qualcomm Snapdragon Ride, Nvidia Drive, etc. However, even within autonomous driving, the software complexity in an ADAS system is quite different from the needs of a fully driverless AV platform. At Cruise, we have chosen to vertically integrate all the way from our AV software stack to the AV hardware platform to the AV itself (see Cruise’s Origin). We believe that this path sets us up for the scaling needs of commercialization.
Taming the AV deployment challenge
In this article, we described the complexity of the AV software stack. We discussed what makes it so unique compared to other AI problems, what makes the AV workload so challenging to deploy and the need for high engineering velocity so the AV can continuously adapt and root out long-tail issues while scaling to new ODDs. Further, scaling AV fleets not only in volume in a single city, but multiple fleets across multiple cities requires a reduction in cost of the platform as volume scales.
The unique demands of the AV compute workload means that off-the-shelf commodity hardware either doesn’t fit the AV use-case or is inefficient and therefore has a negative impact on cost tradeoffs. For these reasons, we have invested in a vertically integrated HW / SW stack. Such vertical integration is crucial to meeting the demands on system-level cost, safety and reliability, which are all critical to scaling. The simplicity and portability of the AV SW deployment ecosystem allows for reuse of the ML toolchain (which is largely abstracted from ML engineers) across our custom SoCs as well as off-the-shelf hardware.
DL frameworks (e.g., TensorFlow, Ptorch) do not treat sparse tensors as a first class datatype, compilers (like XLA, Ptorch JIT, TensorRT) don’t offer support for shape propagation for sparse shapes and support operators that work on sparse types.
DL framework runtimes (like TF runtime, Torch JIT) have an associated overhead at runtime, which in our experiments could be approximately an order of magnitude slower than a fully hand-optimized alternative. Additionally, the non-determinism and not having control of the codebase complicates reliability and maintenance of the codebase.